Nous l’avons annoncé il y a quelques semaines : notre outil de test de performance est maintenant pleinement compatible HTTP/2 et notre référentiel de bonnes pratiques de performance a été adapté pour prendre en compte les particularités de ce protocole. Je vous propose aujourd’hui de revenir en détail sur ce qui a motivé la naissance de HTTP/2, les changements majeurs apportés, mais aussi les différentes bonnes pratiques HTTP/1 dont nous allons devoir nous défaire !
HTTP/1 est mort, vive HTTP/2 !
Ce titre vous surprendra sans doute, et à raison : un avenir sans HTTP/1 est encore très lointain. C’est d’ailleurs mentionné dans la FAQ dédiée du protocole :
Will HTTP/2 replace HTTP/1.x?
The goal of the Working Group is that typical uses of HTTP/1.x can use HTTP/2 and see some benefit. Having said that, we can’t force the world to migrate, and because of the way that people deploy proxies and servers, HTTP/1.x is likely to still be in use for quite some time.
Cela dit, les sites qui ont fait la transition vers HTTP/2 sont déjà très nombreux. Wikipedia, Yahoo ou encore le Financial Times n’en sont que quelques exemples parmi les plus connus.
La plupart des CDN proposent d’ailleurs cette option, ce qui contribue largement à l’adoption de cette nouvelle version du protocole par des centaines de milliers de sites web.
Même si du point de vue applicatif, HTTP/2 est rétrocompatible avec HTTP/1.1 (un site qui fonctionnait sur HTTP/1 fonctionnera aussi sur HTTP/2), l’utilisation du HTTPS est un prérequis pour bénéficier du HTTP/2. Si vous lisez ce blog, vous savez déjà que ce n’est pas la seule raison pour laquelle passer au HTTPs est nécessaire.
De l’autre côté du tunnel, les navigateurs web sont également prêts pour HTTP/2 :
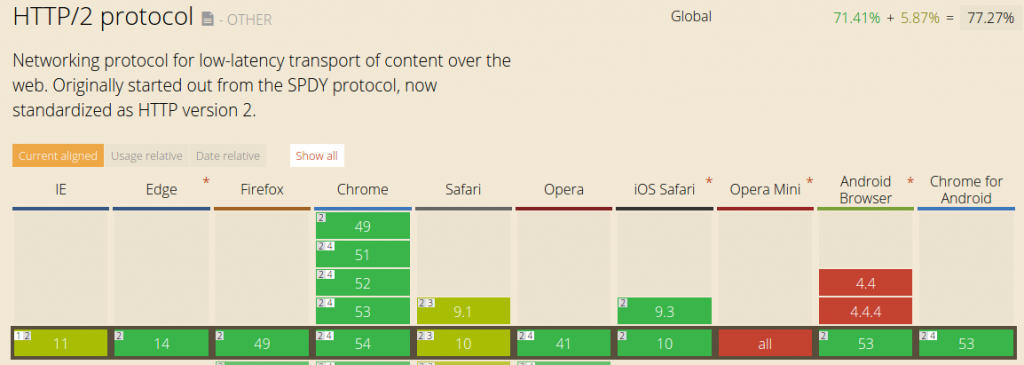
Alors oui, pas de doute, la transition est en marche ! Mais pourquoi HTTP/2 ? Revenons quelques instants sur les limitations du HTTP/1 qui ont motivé cette refonte en profondeur de la communication entre les serveurs et les navigateurs web.
HTTP/1, conçu pour un web d’un autre temps
Les spécifications du protocole HTTP/1.1 sont parues en janvier 1997 à travers la RFC 2068 (mise à jour en 1999). Regardons donc 20 ans en arrière.
Voici à quoi ressemblait par exemple le site de Yahoo :

Et le site du Financial Times :
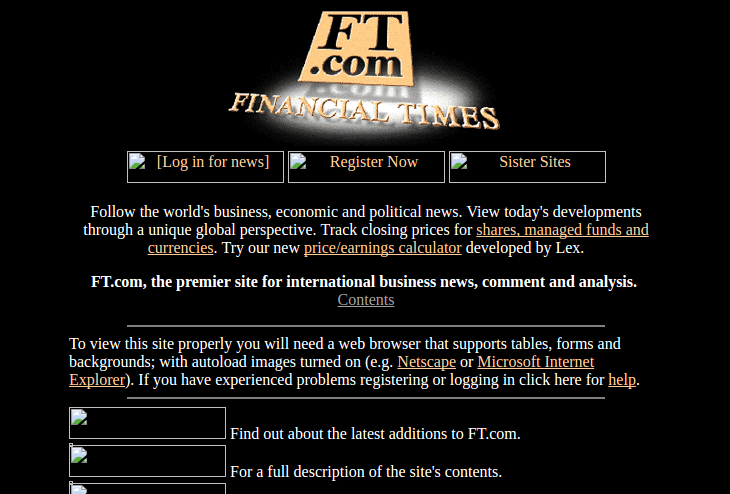
Ce qu’on remarque immédiatement en regardant ces captures, non sans une pointe de nostalgie pour certains d’entre nous : des pages simples, au style minimaliste et avec peu d’images. Et c’est bien normal : le web balbutiait encore (70 millions de “connectés”’ en décembre 1997, contre près de 4 milliards aujourd’hui – source internetworldstats.com), et les connexions étaient évidemment bien moins favorables (ô douce musique du modem 56k).
En 1997, Wikipedia n’existait pas encore, ni Facebook, ni Twitter. Les sites web n’offraient que très peu d’interactions avec les internautes.
C’est donc dans ce contexte que le protocole HTTP/1.1 a pris forme. Un contexte qui a bien changé aujourd’hui :
- le débit moyen mondial est environ 100 fois supérieur à une connexion 56k.
- le poids moyen d’une page est de 2.5Mo (dont plus de 400Ko de javascript).
- l’affichage d’une page nécessite 108 requêtes en moyenne !
Et pour assurer la rapidité de chargement de tels sites web, sur un protocole initialement conçu pour des sites Internet bien plus simples, nous nous appuyons sur de nombreuses bonnes pratiques de performance web. Dont certaines ne sont ni plus ni moins que des contournements des limitations du protocole HTTP/1 !
Des “hacks” dont ils va falloir se défaire sur HTTP/2, puisque ce protocole vise justement à répondre à nos nouveaux besoins. Je vous propose donc de découvrir comment, avec une présentation des principales évolutions apportées par HTTP/2.
Nouveautés HTTP/2, ce qu’il faut retenir
Une seule connexion TCP, multiplexée
C’est sans doute l’une des évolutions les plus notables avec HTTP/2. Jusqu’à présent, une connexion TCP, établie entre le serveur et le navigateur web, ne permettait de récupérer qu’une ressource à la fois.
En HTTP/1 les navigateurs ouvrent plusieurs connexions TCP avec un même serveur, pour paralléliser les requêtes. Mais l’établissement d’une connexion TCP est une opération relativement lente. Et les serveurs web sont limités en ressources, ce pourquoi l’usage de la parallélisation par les navigateurs restait modéré (généralement limitée à 6 connexions par domaine, une forme de “fair-use”). Par conséquent, la centaine de requêtes nécessaires à l’affichage d’une page web se trouve traitée progressivement, chaque requête HTTP devant attendre qu’une précédente s’achève et libère la connexion TCP utilisée. Et ce schéma est particulièrement néfaste lorsque la connexion sous-jacente présente une latence élevée.
Avec HTTP/2, toutes les requêtes sont traitées sur une même connexion TCP pour un domaine donné (multiplexage) ! Certaines pourront se voir accorder une priorité plus importante, pour être privilégiée si la bande passante est limitée. On évite ainsi de répéter le coût de l’initialisation de plusieurs connexions mais aussi qu’une requête chronophage ne monopolise la communication !
Enfin, la communication n’est plus effectuée en mode texte, mais en binaire : cela permet d’une part un traitement plus performant, et d’autre part de diminuer le volume de données qui transitent.
Compression des en-têtes HTTP
Avec le protocole HTTP/1, les en-têtes HTTP sont des textes clef:valeur, et sont souvent répétées, totalement à l’identique, sur chaque requête et chaque réponse. Généralement ces en-têtes ne sont pas très nombreux ni très verbeux, mais le phénomène de répétition finit par rendre leur impact significatif.
Cela peut devenir un problème important lorsque des cookies volumineux sont utilisés.
Avec HTTP/2, les en-têtes sont compressés ! D’autre part, le protocole ne déclare un en-tête dans une requête (ou dans une réponse) qu’en cas de changement par rapport à l’état précédent.
Si vous voulez en savoir plus sur la compression utilisée (HPACK), un très bon billet en français est disponible sur le blog de Stéphane Bortzmeyer.
Serveur Push
C’est probablement la nouveauté apportée par HTTP/2 qui va le plus modifier la perception du protocole pour le développeur front-end ! Jusqu’à présent, le navigateur web analysait la page HTML pour déterminer les contenus qui seront ensuite requêtés (feuilles de style, javascript, images). Mais pourquoi attendre que le navigateur demande une ressource, quand on sait qu’elle va être nécessaire ? C’est exactement le problème que Serveur Push va résoudre en permettant au serveur web de “pousser” un contenu vers le navigateur web s’il le juge utile. On me demande index.html ? Je peux alors décider par moi même d’envoyer styles.css !
Le mécanisme n’est pas aussi simple qu’il n’y paraît, car mal utilisé, le Server Push peut être contre-productif, et la FAQ de la spécification HTTP/2 mentionne d’ailleurs que la définition d’un usage pertinent doit encore faire l’objet d’expérimentations et de recherches.
A noter que certains CDN permettent de définir directement via leur interface des règles pour exploiter le Server Push.
Grâce à ces évolutions, nous allons donc pouvoir abandonner certains “hacks” propres à HTTP/1. Et cela va plus loin, puisque les bonnes pratiques d’hier seront demain les erreurs à éviter : l’application de nombre d’entre elles sera non seulement inutile, mais parfois contre-performante !
Bonnes pratiques HTTP/1, grosses erreurs en HTTP/2
Sprites CSS, concaténation de fichiers CSS ou JS
Tout développeur front-end en aura entendu parler : regrouper les fichiers CSS, les fichiers JS, ou les images de faibles dimensions ensemble permet de limiter le nombre de requêtes HTTP et donc d’accélérer le chargement.
Ce qui était bénéfique en HTTP/1 risque au final d’aller à l’encontre d’une bonne expérience utilisateur en HTTP/2 : la connexion TCP est unique et multiplexée, en regroupant les fichiers, vous allez notamment perdre les bénéfices de priorité sur les différents flux !
A noter que les premiers retours d’expérience sur l’utilisation de HTTP/2 semblent montrer qu’il convient d’éviter malgré tout l’utilisation de micro-fichiers. Si c’est votre cas, appliquer partiellement le principe de concaténation peut rester intéressant !
Domaines Cookie-less
Nous avons parlé plus tôt des en-têtes HTTP, qui se retrouvent répétés sur chaque requête en HTTP/1, ce qui peut être très problématique si le site utilise des cookies un tant soit peu volumineux. Une parade était d’utiliser un domaine dédié pour tous les contenus qui n’avaient pas besoin des informations transmises via les cookies. On éliminait ainsi simplement les données superflues.
Avec HTTP/2, d’une part le problème n’existe plus (en-têtes compressés) mais surtout, le hack du domaine cookie-less devient néfaste, puisqu’il implique inutilement l’utilisation d’une nouvelle connexion TCP et d’une résolution DNS supplémentaire !
Domain Sharding
Autre “hack” HTTP/1, le domain sharding consiste à distribuer les ressources d’une page web sur plusieurs domaines, pour s’affranchir de la limitation de parallélisation des requêtes HTTP des navigateurs web. Cette limite étant associée au domaine, et non au serveur, on peut l’éviter en utilisant plusieurs domaines. Là encore, cela implique des connexions TCP et des résolutions DNS supplémentaires.
Là encore, HTTP/2 a résolu le problème initial, grâce au multiplexage cette fois !
Inlining CSS, JS ou images en base64
Conseillé pour les fragments de CSS, de Javascript ou encore les petites images, l’inlining est une autre technique permettant de réduire le nombre de requêtes HTTP/1.
La nécessité de recourir à cette technique est moins évidente en HTTP/2, puisque l’impact de ces requêtes sera moins marqué grâce au multiplexage. Cette technique conserve les inconvénients déjà présents en HTTP/1, à savoir la perte des bienfaits du cache navigateur pour les ressources concernées, et l’on doit ajouter que cela peut aller à l’opposé des effets recherchés par la prioritisation des flux du multiplexage HTTP/2 !
On notera que l’inlining à des fins d’optimisation du chemin critique, pourra lui être éliminé au profit de l’utilisation du Server Push, même s’il faut garder à l’esprit que ce mécanisme reste relativement expérimental.
Vous l’aurez peut-être anticipé : un site web ayant déployé toutes les bonnes pratiques HTTP/1 pour contourner les limitations propres au protocole, pourrait au final être plus lent avec HTTP/2, puisque cumulant des schémas contre-productifs, que les bienfaits du protocole ne suffiront pas à compenser.
Dareboost permet de tester la performance des sites HTTP/2, mais aussi de comparer les résultats d’une page, en HTTP/1 puis en HTTP/2. Un outil indispensable pour tous ceux qui préparent l’avenir et s’attaquent à cette transition !