We have announced it a couple months ago: our web performance testing tool now fully supports HTTP/2 and our best practices repository has been updated to handle the particularities of this new protocol. Now, let’s go back to the reasons of HTTP/2 emergence and talk about the major changes this protocol brings, and these old HTTP/1 best practices that we will have to give up!
HTTP/1 is dead, long live HTTP/2!
You may find this title surprising, and you should indeed: a future without HTTP/1 is still very far from us. The FAQ dedicated to HTTP/2 highlights it:
Will HTTP/2 replace HTTP/1.x?
The goal of the Working Group is that typical uses of HTTP/1.x can use HTTP/2 and see some benefit. Having said that, we can’t force the world to migrate, and because of the way that people deploy proxies and servers, HTTP/1.x is likely to still be in use for quite some time.
Nevertheless, a lot of websites have already adopted HTTP/2. Here are a few examples among the most famous ones: Wikipedia, Yahoo, The Financial Times…
Most of the CDNs propose it as an option, helping this new protocol to be adopted by thousands and thousands of websites.
Even if HTTP/2 is kind of backward compatible with HTTP/1.1 (a website running on HTTP/1 will also work on HTTP/2), using HTTPs is a requirement to benefit from HTTP/2. If you are a former reader of this blog, you may already know that it’s not the only reason why you should adopt HTTPs.
At the end of the chain, most of the web browsers are HTTP/2 ready too:
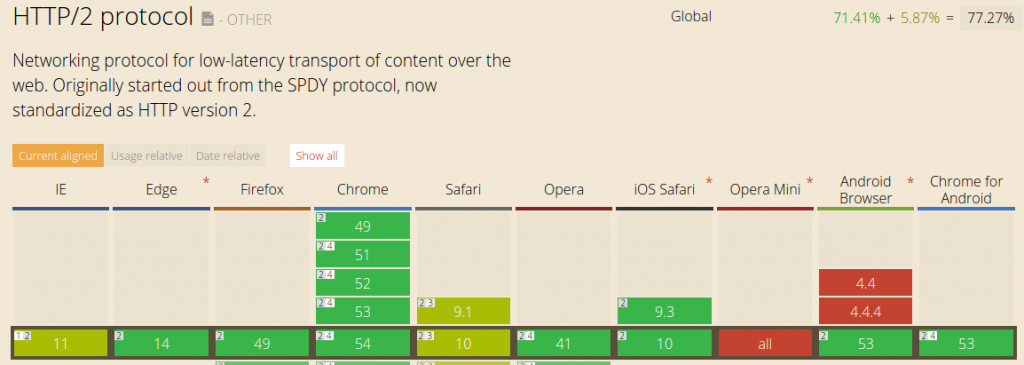
No doubt anymore: change is on its way! But why HTTP/2 was created in the first place? Let’s have a look back to those HTTP/1 limits that have lead to this major update within the communication protocol between web servers and browsers.
HTTP/1: created for the “ancient” web
The HTTP/1 protocol specifications have been published in January 1997, through the RFC 2068 (updated in 1999). Let’s go 20 years back then…
Yahoo website was looking like this:

And the Financial Times like that:
Except this tiny nostalgic feeling some of you may have looking at these screenshots, they remind us what the web was made of then: simple pages, minimalist style and only a few images. Not surprising as the web was still at its beginning: only 70 millions people connecting to internet on december 1997, while we are nearly 4 billions nowadays (source internetworldstats.com). And naturally internet connections were so much slower (did you forget that sweet 56K modem melody?).
In 1997, Wikipedia was not born yet, neither Facebook nor Twitter. Websites were very limited in offering interactions with the users.
HTTP/1.1 protocol was created in this context. Which is totally different today:
- The world average bandwidth is about 100 times higher than a 56K connection.
- The average weight of a web page is 2,5MB (with more than 400KB of javascript).
- One web page requires about 108 requests to load!
To ensure a fast loading of such websites, with a protocol originally designed for much simpler pages, we used to rely on a bunch of web performance best practices… and some of them only exist to bypass the HTTP/1 protocol limitations!
We will have to give up some of those “hacks” with HTTP/2, as this protocol aims at solving these problems by itself. Let’s discover how, by listing the HTTP/2 main evolutions.
HTTP/2 changes to keep in mind
A single multiplexed TCP connection
That is probably the most important evolution brought by HTTP/2. Till now, one TCP connection between a server and a web browser could transfer only one resource at a time. On HTTP/1, the web browsers can open several TCP connections with one same server in order to parallelize the requests. Unfortunately, establishing a TCP connection takes time. Furthermore, web server resources are limited, and so are the number of parallelized connections a browser will use (generally not more than 6 connections by domain, as a “fair-use” rule). As a consequence, the hundred of requests necessary to load one web page are processed gradually: each HTTP request has to wait a previous one to be completed and the TCP connection to be released. This process can be even more harmful with a high latency connection.
With HTTP/2, all the requests can be achieved with a single TCP connection to the concerned domain (multiplexing)! An higher priority can be set on some of these requests in case of a low bandwidth. Thus, not only the “cost” of establishing several connections is avoided but also is the risk to have a time consuming request monopolizing a connection too!
One more change: the communication don’t proceed any longer in text mode but in binary. For a more performant process but also to reduce the volume of transferred data.
HTTP headers compression
With HTTP/1, headers are “key:value” text data, most of time repeated – without any change – for each request and each response. Generally these headers aren’t so numerous neither heavy, but at the scale of a hundred roundtrips, that may lead to a significant impact on performance. That can be a serious issue when heavy cookies are used.
With HTTP/2, headers are compressed! Moreover, this new protocol only declares an header in a request (or an answer) if it changes from its previous state.
For more information about HPACK compression, you can read this KeyCDN blog post.
Push server
Talking about HTTP/2, that’s probably the modification that will the most change the front-end developers perception! Till now, the web browser was parsing the HTML page in order to define the next contents to be requested (stylesheets, javascript, images). Why do we have to wait for the browser request while we know that a resource is necessary? Exactly the kind of issue that Push Server is about to fix, by allowing the web server to directly push an asset to the browser without any matching request in the first place. Index.html is requested? I can decide by myself to send styles.css then! This mechanism is not as simple as it seems to be: if it is used in a wrong way, the Push Server could be counter-productive. The HTTP/2 FAQ mention that the definition of a relevant usage still needs further experimentations and researches.
Note that some CDNs allow to directly define some rules to operate the Server Push via their UI.
Thanks to all these evolutions, we’ll be able to give up some HTTP/1 hacks. Even more: we will have to, as yesterday’s best practices will become the mistakes of tomorrow to be avoided. Keep going with some of them will not only be useless but even harmful for web performance!
HTTP/1 Best practices, HTTP/2 mistakes
CSS sprites, CSS/JS files concatenation
Every front-end developer has already heard about it: concatenate the CSS files, the JS files or small sized images helps to limit the number of requests and so to speed up the page loading.
What was good on HTTP/1 is about to harm the user experience on HTTP/2: with a single and multiplexed TCP connection, by grouping the files, you won’t benefit from HTTP/2 stream prioritization!
Nevertheless, according to the first experience feedback about HTTP/2, note that using tiny files should still be avoided. If it’s your case, keeping on concatenating a part of your assets would still be a good idea!
Cookie-less domains
We previously spoke about HTTP headers, repeated for each HTTP/1 requests, that may become really harmfull if the website rely on heavy cookies. Using a dedicated domain for all the assets that don’t need the cookies data was a solution. This “cookie-less” domain allows to eliminate these unneeded data from the given assets.
First of all, with HTTP/2, the problem doesn’t exist any more (compressed headers).
Furthermore, the “cookie-less domain” hack becomes harmful, as it implies one more – useless – TCP connection and DNS resolution!
Domain Sharding
Another HTTP/1 hack, the domain sharding, consists to shard the web page assets on several domains, in order to bypass the browsers limits for parallelized HTTP requests. As this limit is bound to the domain (and not the server), we can overflow it by multiplying the domains. Unfortunately, this hack implies several new TCP connections and DNS resolutions.
And once again, HTTP/2 has solved the initial problem, thanks to multiplexing this time!
CSS/JS Inlining or base64 images
Regarding CSS or JS snippets or small images, inlining is another solution to reduce the number of HTTP/1 requests. With HTTP/2, this solution is less relevant, as the multiplexing decreases the impact of these requests.
That technique used on a HTTP/2 website keeps the same issues than with HTTP/1: the browser cache benefits are lost for the concerned contents. Furthermore, once again you won’t benefit from stream prioritization.
If your resources were inlined in order to optimize the critical rendering path, the Server Push could be an option. But keep in mind that for now, this mechanism remains relatively experimental.
You may have anticipated the conclusion of this post: a website that has applied all the HTTP/1 best practices to go over the limits of this protocol could be slower with HTTP/2, as it will cumulate counter-productive measures that won’t be balanced by the benefits of the new protocol.
With Dareboost, not only you can test an HTTP/2 website performance but also compare the page speed using HTTP/1 vs HTTP/2. An essential tool for all of those who want to start working on this transition!